Friday, April 20th, 2012
Data Harvest Konferenz in Brüssel von Sonntag bis Dienstag, 6. bis 8. Mai 2012 in Brüssel, Erasmushogeschool, 70 Zespenningenstraat.
Journalismfund.eu, Wobbing.eu und Farmsubsidy.org laden zur „Data Harvest“ Konferenz. Sie bietet Journalisten und Programmierern aus Europa beste Gelegenheiten grenzüberschreitend Kontakte zu knüpfen, sich zu vernetzen, das eigene Wissen zu mehren und auch konkrete Projekte voran zu bringen.
Themenschwerpunkte sind Informationsfreiheitsgesetze und wie man an Daten kommt („Wobbing“), wie man die Daten verarbeitet und visualisiert („Journo Lab“), zudem werden erfahrene Journalisten Werkzeuge und Methoden in praktischen Workshops vorstellen. Ebenso werden die neuen Datenschätze von Farmsubsidy und deren Anwendungsmöglichkeiten vorgestellt.
Referenten sind u.a. Brigitte Alfter, Helena Bengtson, Stefan Candea, Christina Elmer, Thommy Kaas, Nils Mulvad und Paul Myers.
Teilnahmegebühr:
70,- Euro (für die Konferenz und zwei Mittagessen (Montag und Dienstag), zu überweisen an IBAN: BE17 7330 5268 9521 / SWIFT-BIC: KREDBEBB / KBC Bank).
Anmeldungen bis zum 27. April an:
administration@journalismfund.eu – Bewerbungsschluss ist der 27. April!
Detailinformationen, Programm und Liste vorgeschlagener Hotels:
http://www.wobbing.eu/news/data-harvest-conference-2012 .
Thursday, November 17th, 2011
Das NDR-Medienmagazin ZAPP berichtet über Datenjournalismus. Dazu gibt’s die Interviews, die im Beitrag als Kurz-Statements erscheinen, in voller Länge (Links unten).
Das Interview mit Lorenz Matzat, Freier Datenjournalist (24:17 min).
Das Interview mit Christina Elmer, Datenjournalistin “stern” (39:34 min).
Das Interview mit Stefan Wehrmeyer, Aktivist “Open Knowledge Foundation” (08:38 min).
via netzpolitik
Sunday, June 19th, 2011
Welche Personen und Unternehmen spenden eigentlich an die Parteien? Bisher war es recht kompliziert, das herauszufinden: Einmal, weil ohnehin nur alle Spender ab 10.000 Euro veröffentlicht werden. Und dann, weil auch die Informationen über diese Spender schwer zugänglich waren. Einmal im Jahr veröffentlichte der Bundestag auf seiner Webseite eine große PDF-Datei mit den eingescannten Rechenschaftsberichten der Parteien. Man konnte die Dateien nicht automatisch durchsuchen. Wer wissen wollte, ob eine bestimmte Person oder ein bestimmtes Unternehmen zu den Parteispendern gehört, musste sich durch jeden einzelnen Jahrgang und durch mehrere tausend Seiten quälen.
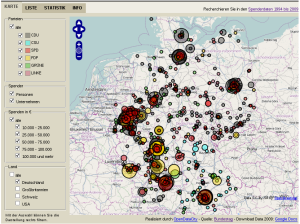 Die taz hat nun die Berichte der Parteien über ihre Spenden der Jahre 1994 bis 2009 aufbereitet und stellt eine Online-Suche zur Verfügung. Die Datenbank wird auch zukünftig aktualisiert, sobald die neuen Berichte erscheinen. Für das Bundestagswahljahr 2009 haben wir die Spender zudem in einer interaktiven Karte dargestellt. So kann jeder sehen, wo in der Nachbarschaft der nächste Parteispender wohnt. Die taz bietet die Daten auch in einem offenen Format zum Download und zur freien Weiterverwendung an.
Die taz hat nun die Berichte der Parteien über ihre Spenden der Jahre 1994 bis 2009 aufbereitet und stellt eine Online-Suche zur Verfügung. Die Datenbank wird auch zukünftig aktualisiert, sobald die neuen Berichte erscheinen. Für das Bundestagswahljahr 2009 haben wir die Spender zudem in einer interaktiven Karte dargestellt. So kann jeder sehen, wo in der Nachbarschaft der nächste Parteispender wohnt. Die taz bietet die Daten auch in einem offenen Format zum Download und zur freien Weiterverwendung an.
Auch die Leser werden einbezogen: Die taz ruft sie dazu auf, die Daten zu durchsuchen und Hinweise für weitere Recherchen zu geben. Gerade im Lokalen erwarten wir viele interessante Rechercheansätze. So wurde die Gertrudis-Klinik in Leun-Biskirchen etwa zum 1. Januar 2011 in den hessischen Landeskrankenhausplan aufgenommen. Statt 18 Betten für gesetzlich Versicherte hat das Krankenhaus seitdem bis zu 140 Kassenplätze. Verantwortlich für die Entscheidung war das CDU-geführte hessische Sozialministerium. Im Jahr 2009 hatte die Gertrudis-Klinik 15.000 Euro an die CDU gespendet. Unsere Leser können weitere sachdienliche Hinweise an die Mailadresse open@taz.de mailen.
Die taz beauftragte opendatacity.de mit der Aufbereitung der PDFs. Die Mitarbeiter programmierten auch die Suchmasken für die maschinenlesbaren Daten. Rund sechs Personen waren in der taz insgesamt mit dem Projekt befasst, etwa einen Monat lang mit welchelnder Intensität. Als Kosten entstanden einige tausend Euro. Wenn man auch die Arbeitszeit der Festangestellten mitberücksichtigt, lagen die Kosten bei grob geschätzten 10.000 Euro. Die taz hat im vergangenen Monat die Kampagne „taz-zahl-ich“ gestartet und ruft ihre Leser dazu auf, freiwillig für die Inhalte auf taz.de zu zahlen. Wir hoffen, so einen Teil der Kosten wieder reinzuholen. Zum Start der Kampagne im April zahlten die Leser mehr als 10.000 Euro, im Mai waren es rund 4.700 Euro.
Sebastian Heiser arbeitet als Redakteur bei der taz
Sunday, April 17th, 2011
Christina Elmer arbeitet bei der Deutschen Presse-Agentur dpa als dienstleitende Redakteurin für aktuelle Infografiken sowie als Trainerin für Web-Recherche und Computer Assisted Reporting (CAR). Zuvor baute sie bei der dpa Deutschlands erste CAR-Redaktion “dpa-RegioData” mit auf. Auf der re:publica hat sie den Vortrag „Datenjournalismus ganz praktisch – Wie Journalisten Daten finden und sicher nutzen“ gehalten und uns erlaubt, Ihre Folien (PDF, 61 kb) zu veröffentlichen. Einige Beispiele für Karten, die die dpa aus Daten produziert hat, fehlen, weil sie zu groß für das PDF waren. Ich finde besonders Folie 16 interessant, in der Christina ihre Erfahrungen dazu, wie verschiedene Datenquellen mit Anfragen umgehen, in einer Matrix dargestellt hat, eingeteilt nach Qualität, Bandbreite, Zugang und Service.
Monday, October 25th, 2010
Die Elektrischen Reporter basteln an einem neuen Video-Format namens ePolitik. Der erste veröffentlichte Testbeitrag kümmert sich um das Thema Open Data: Was ist das, warum gibt es diese Idee, was bewirkt sie bereits, was kann sie noch bewirken, wie ist die Situation in Deutschland – all diese Fragen werden angesprochen. Und natürlich die Frage, wie die rechtliche Situation derzeit aussieht (spoiler alarm: sehr kompliziert! ;-))
Die Macher über die Idee hinter ePolitik:
Internet und Politik stehen in einer wechselseitigen Beziehung zueinander: Einerseits hat sich das Web zu einem politischen Raum entwickelt, zum neuen Ort für politische Debatten, Kommunikation und Protest. Andererseits ist das Netz an vielen Stellen selbst Gegenstand von Politik und Gesetzgebung geworden, wie beispielsweise die heftige Debatte um Netzsperren zeigt. Verändert also die Politik das Netz oder ist es umgekehrt? Entwickelt sich beides aufeinander zu? Mit diesen und anderen Fragen aus der Schnittmenge von Internet und Politik beschäftigt sich ePolitik.
Monday, July 12th, 2010
Am Samstag habe ich gemeinsam mit Lorenz Matzat beim Jahrestreffen des Netzwerks Recherche einen Workshop zum Thema „OpenData und Journalismus“ geleitet. Hier sind die Folien:
Opendata und Journalismus View more presentations from datenjournalist.
Außerdem nochmal mal als PDF (2,4 MB) zum Runterladen.
Friday, April 23rd, 2010
Hauke Johannes Gierow berichtet vom ersten Open Data Hackday in Berlin. Open Data wird Thema eines Workshops mit Lorenz Matzat bei der Jahreskonferenz des Netzwerks Recherche sein, der am 10. Juli um 11.30 Uhr beim NDR in Hamburg stattfindet. Anmeldungen für das Jahrestreffen sind ab sofort möglich.
Der erste deutsche Open Data Hackday (am 17./18. April) ist nun vorbei, und nach dem die meisten Teilnehmer schon während der re:publica fleißig dabei waren, sind Sie wohl größtenteils in einem Zustand euphorischer Erschöpfung wieder nach Hause gekommen. Viele neue Informationen, Anregungen, Ideen, Kontakte und viel Spaß hinterlassen halt auch ihre Spuren.
(more…)
Tuesday, April 20th, 2010
Lorenz Matzat hat vergangene Woche im Blog des Open Data Network den folgenden Versuch einer Definition vorgestellt. Wir veröffentlichen den Text mit freundlicher Genehmigung; er steht unter der Lizenz CC-by-sa/3.0/de. Matzat wird Gast eines Workshops beim Jahrestreffen des Netzwerks Recherche sein, dass am 9. und 10. Juli in Hamburg stattfindet. Den genauen Termin geben wir bekannt, soblad er feststeht.
Das Internet ist nicht arm an Buzzwords – Schlagworten, die für einige Zeit Konjunktur haben und sich eben etablieren oder wieder verschwinden. Data Driven Journalism (DDJ) geistert vermehrt seit vergangenem Jahr durch das Web. Im März 2009 startet die englische Tageszeitung The Guardian auf ihrer Website das Datablog; es ist eingebettet in einen Datastore und dürfte bislang als Referenz für DDJ gelten. Einer breiteren Öffentlichkeit wurde das Thema „Datenjournalismus“ in Deutschland durch die Zeitschrift „M – Menschen Machen Medien“ im März 2010 näher gebracht. Im Periodikum des Fachbereichs Medien der Gewerkschaft ver.di mit einer Auflage von 50.000 Exemplaren ging es um die „Spannende Recherche im Netz“.
(more…)
 Google hat laut „heise online“-Newsticker in Deutschland im September 2006 die 90-Prozent-Hürde beim Marktanteil in Deutschland genommen. Das heißt, mehr als 90 Prozent der Web-Suchanfragen in Deutschland werden bei Google gestellt – und von Google beantwortet. Wie es dazu kam? Google hat sich mit seiner Pagerank-Suchtechnologie und einer einfachen Bedienung die Marktführerschaft erobert und gilt seither als Suchmaschine Nr. 1 im Web. In vielen Browsern ist Google seit Jahren als Standardsuchmaschine voreingestellt.
Google hat laut „heise online“-Newsticker in Deutschland im September 2006 die 90-Prozent-Hürde beim Marktanteil in Deutschland genommen. Das heißt, mehr als 90 Prozent der Web-Suchanfragen in Deutschland werden bei Google gestellt – und von Google beantwortet. Wie es dazu kam? Google hat sich mit seiner Pagerank-Suchtechnologie und einer einfachen Bedienung die Marktführerschaft erobert und gilt seither als Suchmaschine Nr. 1 im Web. In vielen Browsern ist Google seit Jahren als Standardsuchmaschine voreingestellt.